
Typical Monitoring Service Requirements for Industrial Networks – Latency, Scalability & Connectivity
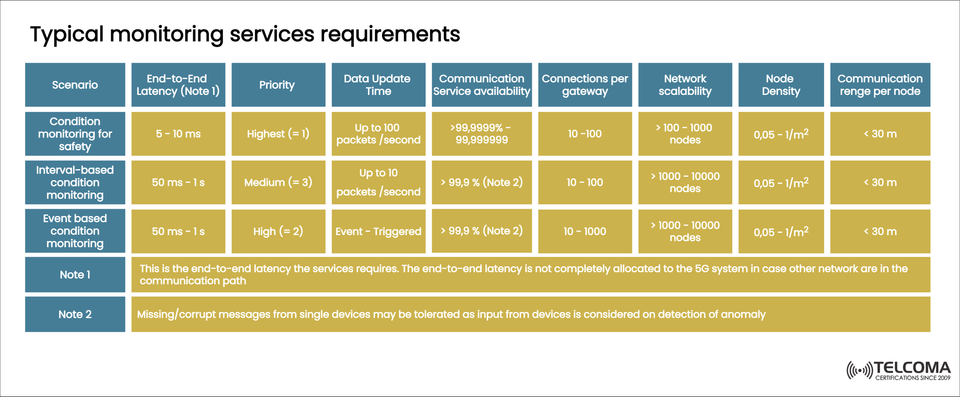

Typical Monitoring Services Needs for Industrial IoT and 5G Networks
As industrial networks shift towards Industry 4.0 and embrace 5G automation, monitoring services become essential for maintaining reliability, safety, and efficiency. The image above outlines the standard monitoring needs for different situations, including safety condition monitoring, interval-based monitoring, and event-driven monitoring.
In this post, we’ll break down these needs and discuss why elements like latency, data update speed, availability of communication, and scalability of the network are crucial for applications that are mission-critical in industrial settings.
Importance of Monitoring Services in Industrial Networks
Today’s factories depend on real-time monitoring to make sure that equipment, processes, and personnel are operating safely and effectively. With the rise of Industrial IoT (IIoT) and 5G networks, monitoring systems can provide:
High reliability for applications where safety is vital
Low latency to ensure swift reactions
Scalable connectivity to accommodate a large number of devices
Efficient data transmission to minimize congestion in the network
Understanding service requirements is key before setting up network infrastructure for manufacturing plants, smart factories, or automated industries.
Three Key Scenarios of Monitoring Services
The image categorizes monitoring into three main scenarios, each with unique performance and network needs.
Scenario End-to-End Latency Priority Data Update Time Service Availability Connections per Gateway Network Scalability Node Density Comm. Range per Node Condition Monitoring for Safety5 – 10 ms Highest (=1)Up to 100 packets/sec> 99.9999%10 – 100100 – 1000 nodes0.05 – 1 /m²< 30 m Interval-Based Condition Monitoring50 ms – 1 s Medium (=3)Up to 10 packets/sec> 99.9% (Note 2)10 – 1001000 – 10000 nodes0.05 – 1 /m²< 30 m Event-Based Condition Monitoring50 ms – 1 s High (=2)Event-triggered> 99.9% (Note 2)10 – 10001000 – 10000 nodes0.05 – 1 /m²< 30 m
- Condition Monitoring for Safety
Safety monitoring is the most critical scenario and requires ultra-low latency (5–10 ms).
Goal: Safeguard employees, machines, and production lines from dangers.
Data Rate: Needs frequent updates (up to 100 packets per second).
Availability: Requires five to six nines (99.9999%) availability, meaning almost no downtime.
Example Use Cases:
Emergency stop systems
Fire detection systems
Gas leak detection
Anomalies in machine vibration
- Interval-Based Condition Monitoring
Interval-based monitoring is okay for less urgent data collection.
Latency: Allows for slightly longer latency (50 ms to 1 second).
Update Frequency: Up to 10 packets per second, suitable for periodic data collection.
Availability: ≥ 99.9% is adequate.
Scalability: Can support more nodes (1,000–10,000).
Example Use Cases:
Tracking temperature
Monitoring energy use
Analyzing predictive maintenance data
- Event-Based Condition Monitoring
This type of monitoring only gets triggered when an event happens, making it more efficient.
Latency: 50 ms to 1 second is acceptable.
Data Transmission: Event-driven, conserving bandwidth when there are no anomalies.
Connections: Capable of handling many nodes (10–1000 per gateway).
Example Use Cases:
Alerts for machine failures
Notifications for threshold breaches
Triggers for quality inspections
Key Parameters Explained
Let’s simplify the technical requirements:
End-to-End Latency: The total time from data generation by a sensor to its reach in the monitoring system. Lower latency is critical for real-time safety applications.
Priority Levels:
Priority 1 – Mission-critical (for safety systems)
Priority 2 – High importance (for event-triggered monitoring)
Priority 3 – Medium importance (for routine updates)
Data Update Time: How often data is transmitted. Faster update rates are vital for rapidly changing parameters like vibrations or pressure.
Communication Service Availability: Shows how reliable the network is. In safety-critical setups, even a second of downtime can be disastrous, which is why 99.9999% uptime is necessary.
Connections per Gateway: The number of devices that can connect to one access point or gateway.
Network Scalability: Ensures the network can expand to accommodate thousands of devices in large manufacturing settings.
Node Density: Indicates how many devices can fit in a specified area (per square meter).
Communication Range per Node: Shows the typical coverage area, in this case, < 30 meters, which fits with short-range industrial networks (Wi-Fi 6, private 5G, or proprietary wireless setups).
Design Considerations for Industrial Networks
When implementing monitoring services in a factory or industrial space, network designers should think about:
Selecting the Appropriate Network Technology: Whether to use private 5G, Wi-Fi 6, or fieldbus networks based on latency needs.
Gateway Placement: Making sure coverage is optimized while reducing interference.
Quality of Service (QoS): Giving priority to safety-critical traffic over regular monitoring data.
Redundancy: Planning networks with backup paths to meet high availability demands.
Security: Safeguarding data integrity, especially critical for safety monitoring systems.
Why 5G is a Game-Changer for Monitoring
5G networks offer several benefits for industrial monitoring services:
Ultra-Reliable Low-Latency Communication (URLLC): Ideal for safety-critical monitoring tasks.
Massive Machine-Type Communications (mMTC): Supports a high density of IoT devices.
Network Slicing: Creates dedicated virtual networks for safety monitoring, separate from normal traffic.
Conclusion
Monitoring services are foundational to modern industrial automation, ensuring safety, efficiency, and reliability. By grasping elements like latency, priority, update frequency, and scalability, network designers can create effective solutions tailored to various application needs.
With 5G and advanced IoT frameworks, industries can achieve real-time visibility, predictive maintenance, and prompt reactions to critical issues — ultimately leading to safer and more efficient production environments.